

In this two-part series, we'll show you how we successfully implemented zero-downtime Postgres migrations on Amazon RDS. Part one focuses on how we used an open-source tool, Bucardo. Follow along as we guide you through the process of building a new database while keeping it synchronized with your live database during the migration.
With our infrastructure on the Amazon Web Services(AWS) cloud, it’s usually a simple task patching up our databases. Our engineering team takes pride in keeping our tools and dependencies up to date as much as possible, so we regularly rope these maintenance tasks into our schedule.
But not all of these tasks are as easy as pressing a button on the AWS console. We encountered one of these more complex tasks when it was time to make a mandatory version upgrade to our production databases.
Handling this database migration well was a business-critical task because zero downtime was non-negotiable. We needed to ensure no customer data was lost during the process and that nothing interfered with new API calls and developer sign-ups.
Let's walk through how we did this with Bucardo.
Why are we using Bucardo to do this?
Many applications use Smartcar’s platform as a primary way to connect to vehicles throughout the day. If we’re not up and running, vehicle owners can’t access our customers’ solutions.
Migrating your database while incurring downtime is relatively easy but with clear drawbacks to your product reliability. Your process would look like this:
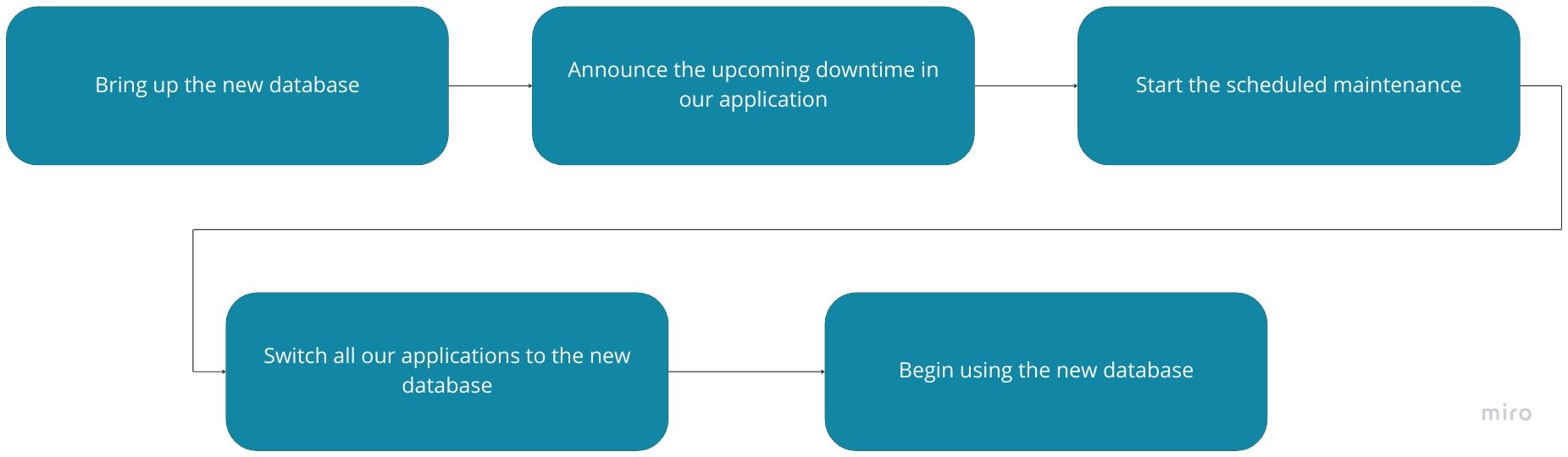
Since we were only updating the underlying infrastructure, we could easily spin up an alternate RDS cluster and restore data from a certain point in time. But this becomes tricky if we want to keep our database updated and running even as our client applications are switching one by one. To make this happen, we needed to switch up the process.
Taking those conditions into account, our migration would look like this instead:
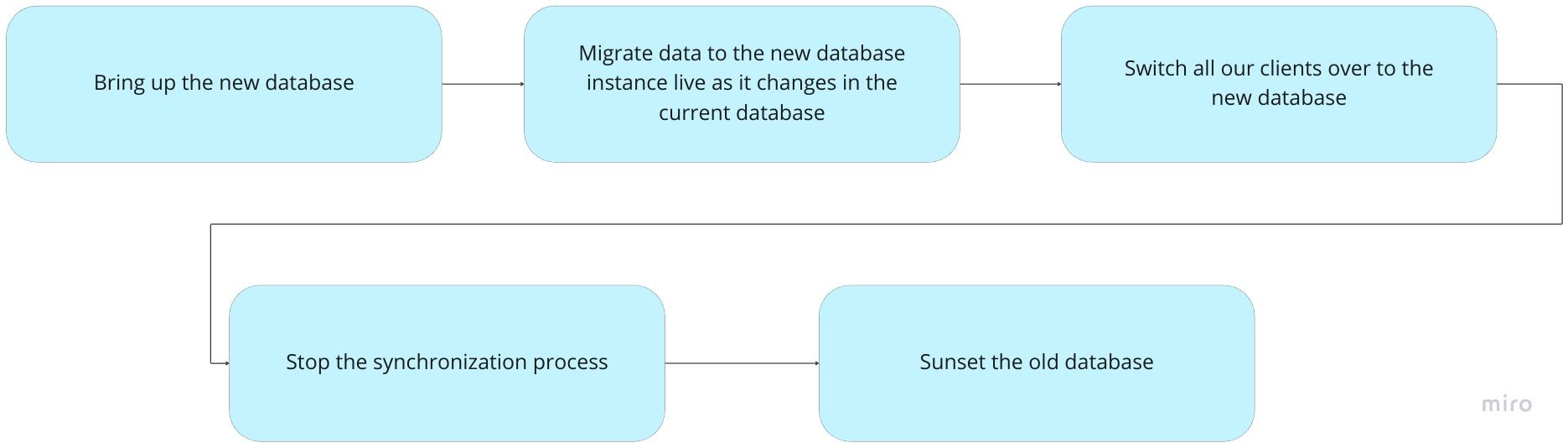
To achieve step two of this new process, we’re using Bucardo, an open-source tool for replicating PostgreSQL data. We used Bucardo primarily for two primary operations:
- Backfilling existing data from the old database into the new one.
- Replicating live changes on the old database into the new database while the clients are switching over
Now let's jump into Bucardo's setup, configuration, and usage!
How to set up Bucardo
Our databases reside in a secure private subnet in AWS. The server where we run Bucardo needs access to both the source (old) and the destination (new) databases. We also need SSH to access the server we want to run Bucardo on and set it up.
There are many best practices for doing this in different ways, but for the sake of this tutorial, let's keep it simple.
1. Create an EC2 Instance to run Bucardo in a subnet with the following:
➡ Access to the source database
➡ Access to the target database
➡ Key-based SSH access
Bucardo doesn't have an official docker container, but we’ll want to install and run Bucardo in an isolated container. So, we built an Ubuntu container to install and run Bucardo from there.
2. Install Docker Engine with the instructions found here
3. Run an Ubuntu container and log in to the bash shell
4. Install all dependencies following these instructions
5. Set up the internal Postgres installation that will be used by Bucardo.Edit
Edit `/etc/postgresql/13/main/pg_hba.conf` to trust all:
6. Restart Postgres for the changes to take effect
7. Continue with the Bucardo setup
You should see the below as a confirmation. Type `P` to proceed.
How to configure Bucardo for migration
Set up complete! Now we’re ready to run a migration.
1. Prepare the target database with all tables from the source database.
Bucardo does not migrate over schemas, only data.
An easy way of doing the schema migration is to utilize the pg_dump command with the --schema-only flag.
2. Create your target database and import the schema into it.
3. Add the databases to Bucardo to let Bucardo know what will be used in the sync process.
We can label these databases as the “source” and “target” for convenience and then to bucardo using the following commands.
The databases that we’ve added are reflected in Bucardo’s internal database. However, Bucardo needs the password to those databases to act as the intermediary between the two.
We could pass an additional command line parameter `pass=<password string>`, but passwords with special characters end up truncated, which causes the command to fail. To avoid this, we recommend logging in to the Bucardo local DB and adding the password yourselves.
4. Configure a sync using the two databases created above.
`onetimecopy=1` is set on the Bucardo sync to indicate that we want the initial data in the source database to be copied into the target database. See the Bucardo docs for additional options.
Now we have everything ready to constantly sync the target database with any changes reflected on the source database.
How to initiate the process
The last thing left to do is start the sync!
Here are some useful commands to start, stop or monitor the status (you can find other useful CLI commands that can be found on official Bucardo docs).
- `bucardo start` to start the sync
- `tail -f /var/log/bucardo/log.bucardo` to stream the live logs
- `bucardo status` to see the status of all the sync operations going on
- `bucardo stop` to stop the sync
What we’ll cover next
We just looked into setting up the Bucardo sync with two databases, which is one of the most important steps of the database migration we’re performing. Now that Bucardo is up and running, we can start focusing on switching clients to the new database.
Smartcar has multiple services depending on our database, which means they have to switch over from our source to our target database simultaneously or with a minimum delay.
Managing the difference in deployment time of different services was a major challenge we needed to solve. But we came up with a way to handle this issue with homegrown configuration management magic.
Stay tuned to the Smartcar engineering blog for our next update, or subscribe to our newsletter below!

